第八章 缓存优化
问题说明
用户数量多,系统访问量大频繁访问数据库,系统性能下降,用户体验差
环境搭建
maven坐标
在项目的pom.xml文件中导入spring data redis的maven坐标
1 | <!-- Redis --> |
配置文件
在项目的application.yml中加入redis相关配置:
1 | spring: |
配置类
在项目中加入配置类RedisConfig:
1 |
|
可以用StringRedisTemplate就不用配置类
linux启动redis
1 | /usr/local/redis-4.0.0/src/redis-server /usr/local/redis-4.0.0/redis.conf |
缓存短信验证码
实现思路
前面我们已经实现了移动端手机验证码登录,随机生成的验证码我们是保存在HttpSession中的。现在需要改造为将验证码缓存在Redis中,具体的实现思路如下:
在服务端
UserController中注入RedisTemplate对象,用于操作Redis1
2
private RedisTemplate redisTemplate;在服务端UserController的sendMsg方法中,将随机生成的验证码缓存到Redis中,并设置有效期为5分钟
1
2// 将生成的验证码缓存到Redis中,并且设置有效期为5分钟
redisTemplate.opsForValue().set(phone, code, 5, TimeUnit.MINUTES);在服务端UserController的login方法中,从Redis中获取缓存的验证码,如果登录成功则删除Redis中的验证码。
1
2
3
4
5
6
7// 从Redis中获取缓存的验证码
Object codeInSession = redisTemplate.opsForValue().get(phone);
// 登录业务代码....
// 如果用户登录成功,则删除Redis中缓存的验证码
redisTemplate.delete(phone);
缓存菜品数据
实现思路
前面我们已经实现了移动端菜品查看功能,对应的服务端方法为DishController的list方法,此方法会根据前端提交的查询条件进行数据库查询操作。在高并发的情况下,频繁查询数据库会导致系统性能下降,服务端响应时间增长。现在需要对此方法进行缓存优化,提高系统的性能。
具体的实现思路如下:
改造
DishController的list方法,先从Redis中获取菜品数据,如果有则直接返回,无需查询数据库;如果没有则查询数据库,并将查询到的菜品数据放入Redis。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16List<DishDto> dishDtoList = null;
// 动态的构造key
String key = "dish_" + dish.getCategoryId() + "_" + dish.getStatus();
// 从Redis中获取缓存数据,
dishDtoList = (List<DishDto>) redisTemplate.opsForValue().get(key);
if(dishDtoList != null) {
// 如果存在,直接返回,无需查询数据库
return R.success(dishDtoList);
}
// 如果不存在,需要查询数据库,
...
...
...
// 将查询到的菜品数据缓存到Redis
redisTemplate.opsForValue().set(key, dishDtoList, 60, TimeUnit.MINUTES);改造
DishController的save和update方法,加入清理缓存的逻辑。保证数据库中的数据和Redis中的数据一致。1
2
3
4
5
6
7//方法一:清理所有菜品缓存数据
//Set keys = redisTemplate.keys("dish_*");
//redisTemplate.delete(keys);
//方法二:清理某个分类下面的菜品缓存数据
String key="dish_" + dishDto.getCategoryId() + "_" + dishDto.getStatus();
redisTemplate.delete(key);
注意:在使用缓存过程中,要注意保证数据库中的数据和缓存中的数据一致,如果数据库中的数据发生变化,需要及时清理缓存数据。
Spring Cache
Spring Cache介绍
Spring cache是一个框架,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能。
Spring Cache提供了一层抽象,底层可以切换不同的cache实现。具体就是通过CacheManager接口来统一不同的缓存技术。
CacheManager是Spring提供的各种缓存技术抽象接口。
针对不同的缓存技术需要实现不同的CacheManager:
Spring Cache常用注解

在spring boot项目中,使用缓存技术只需在项目中导入相关缓存技术的依赖包,并在启动类上使用@EnableCaching开启缓存支持即可。
例如,使用Redis作为缓存技术,只需要导入Spring data Redis的maven坐标即可。
Spring Cache使用方式
在Spring Boot项目中使用Spring Cache的操作步骤(使用redis缓存技术);
1、导入maven坐标
spring-boot-starter-data-redis、spring-boot-starter-cache
2、配置application.yml
1 | spring: |
3、在启动类上加入@EnableCaching注解,开启缓存注解功能
4、在Controller的方法上加入@Cacheable、@CacheEvict等注解,进行缓存操作
缓存套餐数据
实现思路
前面我们已经实现了移动端套餐查看功能,对应的服务端方法为SetmealController的list方法,此方法会根据前端提交的查询条件进行数据库查询操作。在高并发的情况下,频繁查询数据库会导致系统性能下降,服务端响应时间增长。现在需要对此方法进行缓存优化,提高系统的性能。
具体的实现思路如下:
- 导入
Spring Cache和Redis相关maven坐标 - 在
application.yml中配置缓存数据的过期时间 - 在启动类上加入
@EnableCaching注解,开启缓存注解功能 - 在
SetmealController的list方法上加入@Cacheable注解 - 在
SetmealController的save和delete方法上加入@CacheEvict注解
代码改造
在pom.xml文件中导入maven坐标:
1 | <dependency> |
在application.yml中配置缓存数据过期时间:
1 | cache: |
在启动类@EnableCaching注解
在list方法上添加注解,实现在redis里添加缓存:
1 |
在update,add,delete方法上添加注解,清除缓存:
1 | // 修改后讲setmealCache分类下的所有缓存全部删除 |
注意:要让R实现Serializable接口(序列化),注解才能生效
第九章 读写分离
问题分析
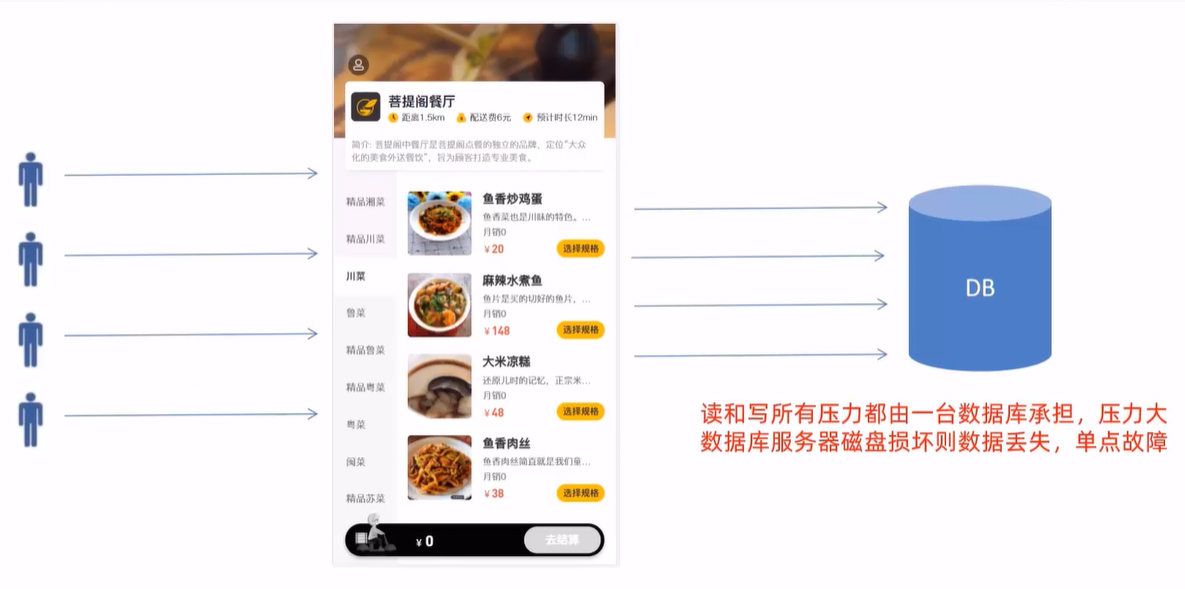
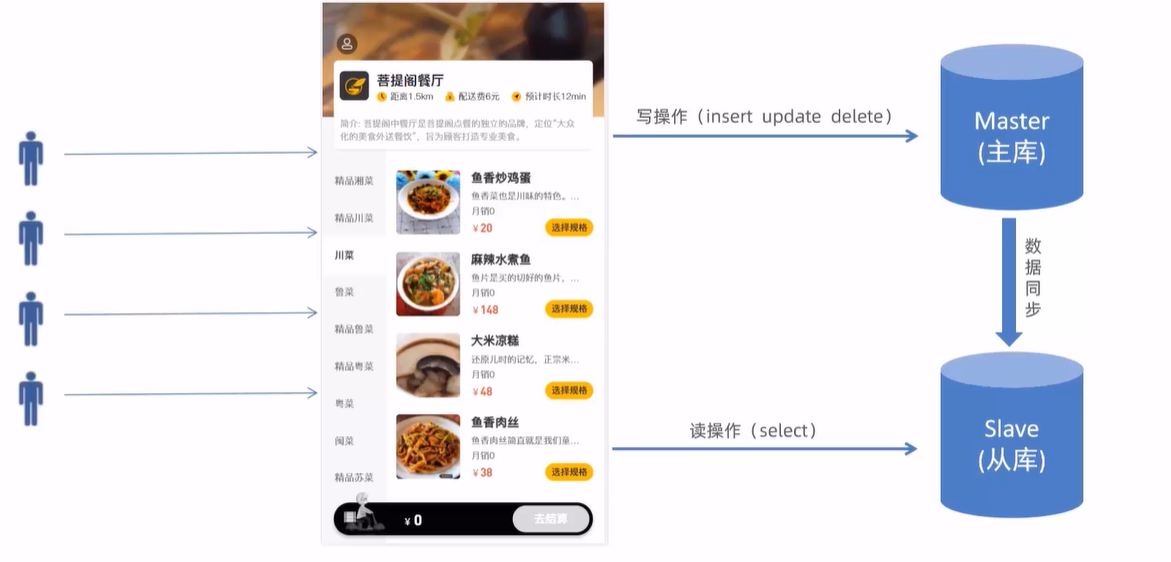
Mysql主从复制
介绍
MysSQL主从复制是一个异步的复制过程,底层是基于Mysql数据库自带的二进制日志功能。就是一台或多台AysQL数据库(slave,即从库)从另一台MysQL数据库(master,即主库)进行日志的复制然后再解析日志并应用到自身,最终实现从库的数据和主库的数据保持一致。MySQL主从复制是MysQL数据库自带功能,无需借助第三方工具。
MysQL复制过程分成三步:
- master将改变记录到二进制日志( binary log)
- slave将master的binary log拷贝到它的中继日志(relay log)
- slave重做中继日志中的事件,将改变应用到自己的数据库中
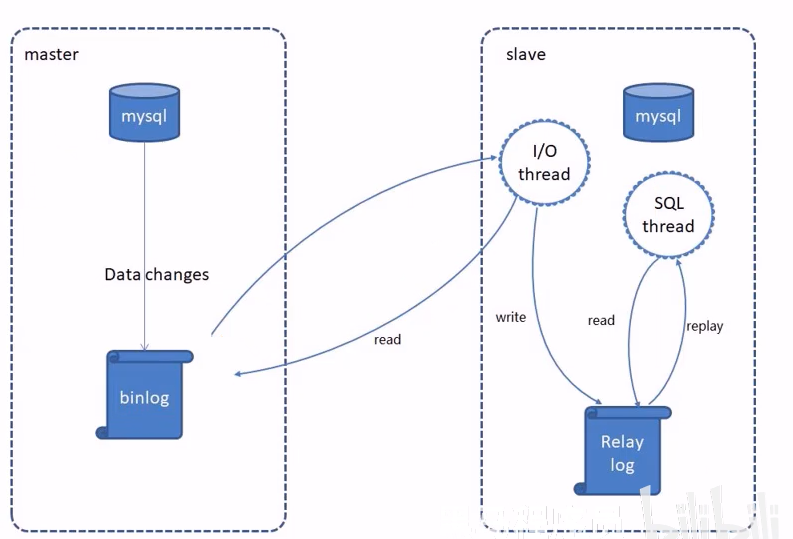
配置-前置条件
提前准备好两台服务器,分别安装Mysql并启动服务成功
- 主库Master 192.168.188.100
- 从库slave 192.168.188.101
注意:克隆的虚拟机需要修改数据库的uuid
配置-主库Master
第一步:修改Mysq1数据库的配置文件/etc/my.cnf
1 | [mysqld] |
第二步:重启Mysql服务systemctl restart mysqld
第三步:登录Mysql数据库,执行下面SQL
1 | GRANT REPLICATION SLAVE ON *.* to 'xiaoming'@'%' identified by 'Root@123456'; |
注:上面SQL的作用是创建一个用户xiaoming,密码为Root@123456,并且给xiaoming用户授予REPLICATION SLAVE权限。常用于建立复制时所需要用到的用户权限,也就是slave必须被master授权具有该权限的用户,才能通过该用户复制。
第四步:登录Mysql数据库,执行下面SQL,记录下结果中File和Position的值
1 | show master status; |
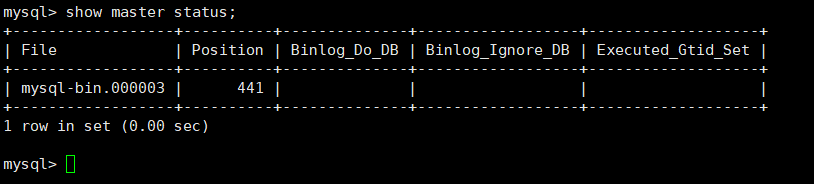
注:上面SQL的作用是查看Master的状态,执行完此SQL后不要再执行任何操作
配置-从库Slave
第一步:修改Mysq1数据库的配置文件/etc/my.cnf
1 | [mysqld] |
第二步:重启Mysql服务systemctl restart mysqld
第三步:登录Mysql数据库,执行下面SQL
1 | change master to |
第四步:登录Mysql数据库,执行下面SQL,查看从数据库的状态show slave status;
读写分离案例
背景
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。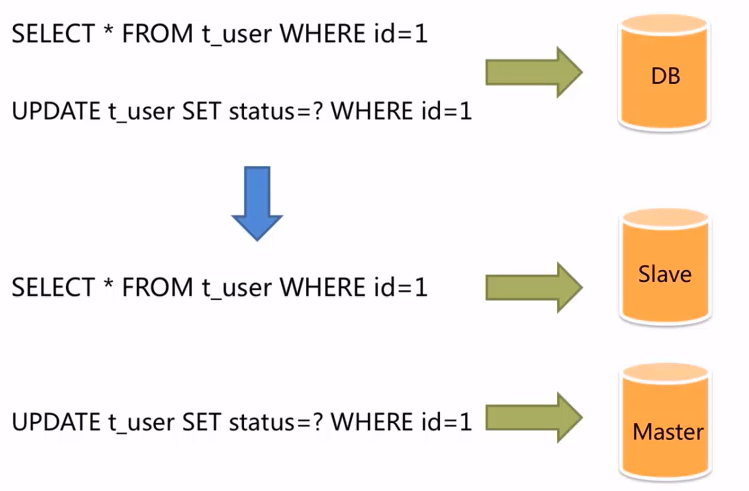
Sharding-JDBC介绍
Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
使用Sharding-JDBC可以在程序中轻松的实现数据库读写分离。
- 适用于任何基于JDBC的ORM框架,如: JPA, Hibernate,Mybatis, Spring JDBC Template或直接使用JDBC。
- 支持任何第三方的数据库连接池,如:DBCP,C3PO,BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
1 | <dependency> |